Flow.combineの内部実装がすごい話
Kotlin CoroutinesのFlowを使っている場合、UI状態の統合等でFlow.combineを使うことが多いと思います。
Kotlin CoroutinesはOSSになっており、その実装を簡単に読むことができます。
Flow.combineはどうやって実装されているのか気になり、読んでみると、思った以上に細かいところに気を配った丁寧な実装になっていて驚きました。
今回はそのFlow.combineの実装を自分で再現するという流れで、公式のFlow.combineの工夫されている点や、複雑なFlowを自作する方法について学びたいと思います。
Flow.combineの動作
Flow.combineは2つ以上のFlowから値を受け取り、それらの値を組み合わせて新しい値を作成するFlowを作ります。
例えば、flow1とflow2の値の合計を出力するFlowは以下のように作れます。
val outputFlow = flow1.combine(flow2) { t1, t2 ->
t1 + t2
}上記は、以下のように書くこともできます。
val outputFlow = combine(flow1, flow2) { t1, t2 ->
t1 + t2
}いずれかのFlowが更新されると、それぞれのFlowの最新の値をもとに新しい値が再計算されます。
すべてのFlowの最初の値が用意されるまで、値が流れないことにも注意してください。
図にすると、以下のようになります。
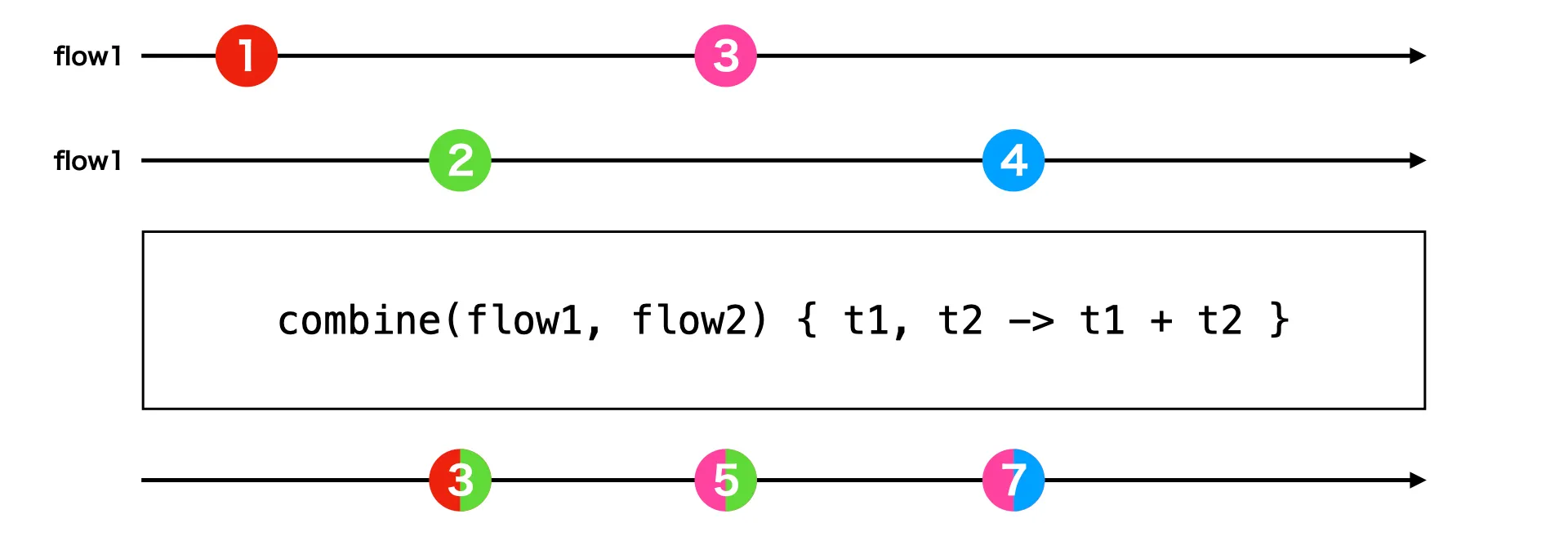
他に複数のFlowを組み合わせるものに、zipやmergeというものもあるので、混合しないように注意してください。
簡単な実装
このFlow.combineを自分で実装してみましょう。
簡単な実装方法として、以下のようなコードが浮かぶと思います。
fun <T1, T2, R> combine(
flow: Flow<T1>,
flow2: Flow<T2>,
transform: suspend (a: T1, b: T2) -> R
): Flow<R> = combine(arrayOf(flow, flow2)) {
@Suppress("UNCHECKED_CAST")
transform(it[0] as T1, it[1] as T2)
}
inline fun <T, R> combine(
flows: Array<Flow<T>>,
crossinline transform: suspend (Array<T>) -> R
): Flow<R> = channelFlow {
val size = flows.size
val latestValues = Array(size) { UNINITIALIZED }
flows.forEachIndexed { index, flow ->
launch {
flow.collect { value ->
latestValues[index] = value
if (latestValues.all { it != UNINITIALIZED }) {
@Suppress("UNCHECKED_CAST")
send(transform(latestValues as Array<T>))
}
yield() // 各Flowが`emit`する機会を与える
}
}
}
}
private object UNINITIALIZED順番に解説していきます。
今回用意するのは2つのFlowを統合するためのオペレーターですが、より多くのFlowにも対応できるよう、FlowをArrayの中に入れて一般化します。
fun <T1, T2, R> combine(
flow: Flow<T1>,
flow2: Flow<T2>,
transform: suspend (a: T1, b: T2) -> R
): Flow<R> = combine(arrayOf(flow, flow2)) {
@Suppress("UNCHECKED_CAST")
transform(it[0] as T1, it[1] as T2)
}すべてのFlowを監視し、latestValuesに最新の値を格納していきます。
inline fun <T, R> combine(
flows: Array<Flow<T>>,
crossinline transform: suspend (Array<T>) -> R
): Flow<R> = channelFlow {
val size = flows.size
val latestValues = Array(size) { UNINITIALIZED }
flows.forEachIndexed { index, flow ->
launch {
flow.collect { value ->
latestValues[index] = value
/* ... */
}
}
}
}初期状態として、UNINITIALIZED というオブジェクトを用意しています。
nullを使わないのはFlowの値としてnullを使うこともできるので、それと初期状態を区別するためです。
他に考えられる方法として、以下のように Holder クラスを用意することで null と初期状態を区別することができます。
class Holder<T : Any?>(val value: T)
val uninitialized: Holder<Int?>? = null
val initializedNull: Holder<Int?>? = Holder(null)
val initializedInt: Holder<Int?>? = Holder(1)こちらの方が型安全になりますが、クラスの生成はコストがかかることがあるのでAny?を使うことがあります。
すべての初期値が決定されたタイミング、すなわちlatestValuesのすべての値がUNINITIALIZEDでなくなったタイミングから出力のFlowに値を排出していきます。
flow.collect { value ->
latestValues[index] = value
if (latestValues.all { it != UNINITIALIZED }) {
@Suppress("UNCHECKED_CAST")
send(transform(latestValues as Array<T>))
}
yield() // 各Flowが`emit`する機会を与える
}Flowのcollect内部でyieldを呼び出しているのは他のFlowがemitする機会を担保するためです。
Dispatchers.Main等の単一スレッドのディスパッチャーを使っている場合、一つのFlowが連続で値をemitしているとそのFlowのみが連続して処理され、他のFlowの値を受け取れないという問題が発生します。
それを防ぐため、yieldを呼び出すことで他のFlowに処理を譲ることができます。
複数のCoroutinesを起動し、その中でFlowを出力する場合はflowの代わりにchannelFlowを使う必要があることに注意してください。
スレッドセーフにする
上記のコードはだいたい期待通りに動作しますが、Dispatchers.Default等の複数スレッドを利用できるDispatcherを使うと、競合状態が発生することがあります。
Dispatchers.Default等を使うと、Flowを監視するために起動しているCoroutinesが別スレッドで起動されます。
その際、複数スレッドで latestValuesを共有して読み取り及び書き込みを行うことになるため、不整合な状態が生まれる可能性があります。
解決にはMutexを使うなどいくつか方法がありますが、今回はChannelを使う方法を紹介します。
すべてのFlowのイベントを集めるresultChannelを用意し、そのChannel経由でのみ出力Flowの作成を行います。
inline fun <T, R> combine(
flows: Array<Flow<T>>,
crossinline transform: suspend (Array<T>) -> R
): Flow<R> = flow {
val size = flows.size
val latestValues = Array(size) { UNINITIALIZED }
val resultChannel = Channel<IndexedValue<T>>()
coroutineScope {
flows.forEachIndexed { index, flow ->
launch {
flow.collect { value ->
resultChannel.send(IndexedValue(index, value))
yield() // 各Flowが`emit`する機会を与える
}
}
}
for (element in resultChannel) {
latestValues[element.index] = element.value
if (latestValues.all { it != UNINITIALIZED }) {
@Suppress("UNCHECKED_CAST")
emit(transform(latestValues as Array<T>))
}
}
}
}こうすることで、latestValuesの読み書きや出力Flowへの排出を単一スレッドで安全に行うことができるようになります。
出力Flowへの排出が既存のCoroutine Scope内になったため、channelFlowではなくflowに変更しています。
スレッド競合については以前書いた「Kotlin Coroutinesで共有リソースを扱う」も確認してみてください。
Flowのcloseに対応する
Flowはすべてのイベントを排出したタイミングでストリームをcloseすることができます。
公式のFlow.combineでは、監視しているすべてのFlowが閉じたタイミングで出力のFlowも閉じるようになっています。
これを実装してみましょう。
inline fun <T, R> combine(
flows: Array<Flow<T>>,
crossinline transform: suspend (Array<T>) -> R
): Flow<R> = flow {
val size = flows.size
val latestValues = Array(size) { UNINITIALIZED }
val resultChannel = Channel<IndexedValue<T>>()
val nonClosed = AtomicInteger(size)
coroutineScope {
flows.forEachIndexed { index, flow ->
launch {
try {
flow.collect { value ->
resultChannel.send(IndexedValue(index, value))
yield() // 各Flowが`emit`する機会を与える
}
} finally {
// Flowが一つも残っていなければチャンネルを閉じる
if (nonClosed.decrementAndGet() == 0) {
resultChannel.close()
}
}
}
}
for (element in resultChannel) {
/* ... */
}
}
}Flowをcollectしている場所をtry-finallyで囲って、終了時にnonClosedをデクリメントしていきます。
すべてのFlowがcloseされると、nonClosedも0になるので、その時チャンネルもcloseします。
チャンネルがcloseされると、 element in resultChannelの箇所を抜け、出力Flowも終了します。
先程も言った通り、ここは複数スレッドで呼び出される可能性があるため、AtomicInteger等を使ってスレッドセーフにする必要があります。
AtomicIntegerはJVMでしか使えないため、公式のFlow.combineではkotlinx.atomicfuが使われていました。
不要な出力を減らす
複数のFlowにほぼ同時に出力があった場合に、何度も変換処理が実行されるのは無駄が多いと言えます。
例えば、以下のように2つのFlowを同時に編集しようとしたとします。
val flow1 = MutableStateFlow("a1")
val flow2 = MutableStateFlow("b1")
launch {
combine(flow1, flow2) { t1, t2 -> "$t1:$t2" }
.collect { println(it) }
}
launch {
delay(100)
flow1.value = "a2"
flow2.value = "b2"
}この際、上記の実装だと以下のように出力されます。
a1:b1
a2:b1
a2:b2ただし、a2:b1という出力は実際にはほとんど必要なく、スキップしてくれると理想的と言えるでしょう。
a1:b1
a2:b2図に書き表すと、以下のようになります。
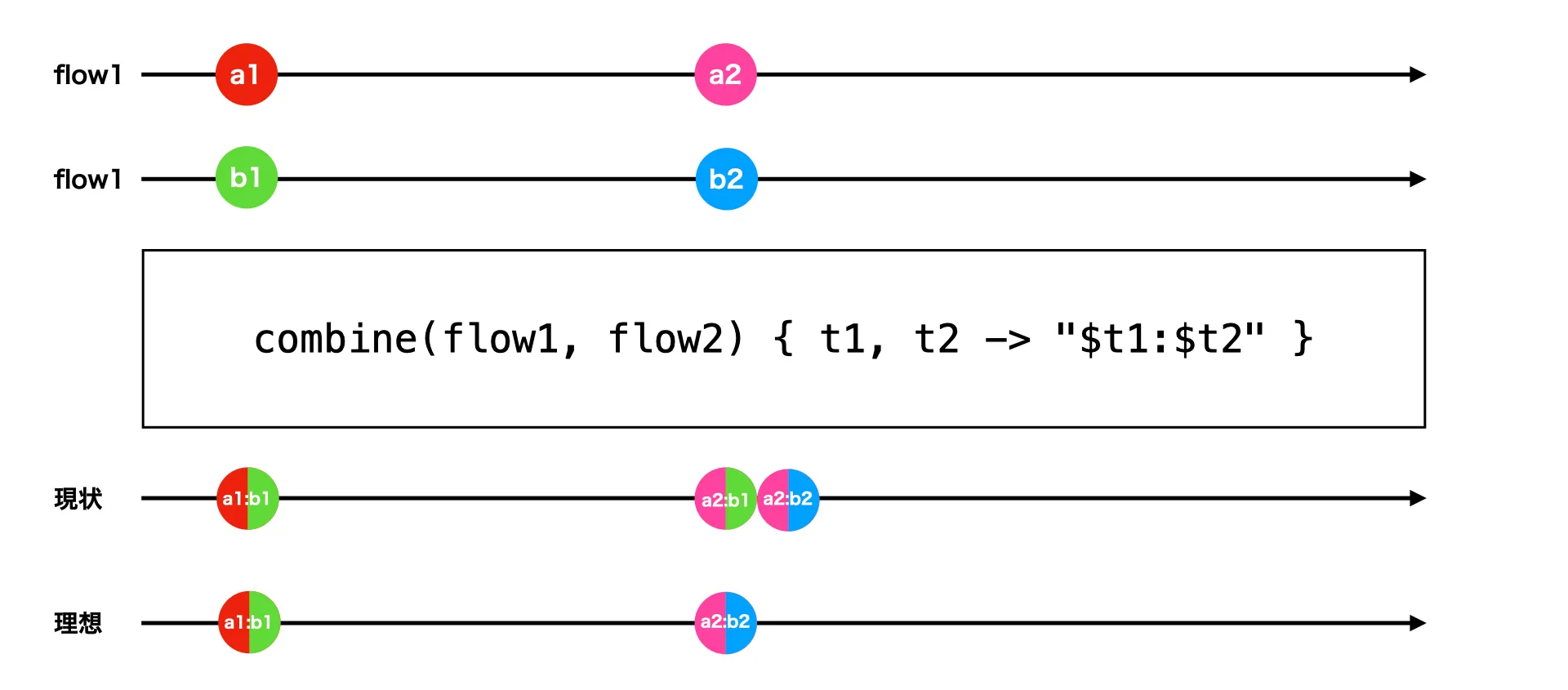
公式のFlow.combineでは複数のFlowで同時に値が流れたときは、最新の値でのみ変換処理が行われるように制御されています。
この動きを再現してみたいと思います。
inline fun <T, R> combine(
flows: Array<Flow<T>>,
crossinline transform: suspend (Array<T>) -> R
): Flow<R> = flow {
val size = flows.size
val latestValues = Array(size) { UNINITIALIZED }
val resultChannel = Channel<IndexedValue<T>>(size)
val nonClosed = AtomicInteger(size)
coroutineScope {
flows.forEachIndexed { index, flow ->
launch { /* ... */ }
}
while (true) {
// チャンネルが閉じられていたら、何もせずに終了する
var element = resultChannel.receiveCatching().getOrNull() ?: break
while (true) {
val index = element.index
latestValues[index] = element.value
element = resultChannel.tryReceive().getOrNull() ?: break
}
if (latestValues.all { it != UNINITIALIZED }) {
@Suppress("UNCHECKED_CAST")
emit(transform(latestValues as Array<T>))
}
}
}
}1つ目のループでChannel.receiveCatchingを使って、チャンネルのイベントを待機します。
チャンネルがクローズされていたら、getOrNullの結果がnullになるので、そのままループを抜けて終了します。
その後、2つ目のループを起動し、その中でChannel.tryReceiveを使ってさらにイベントを受け取っていきます。
Channel.tryReceiveはsuspend functionではなく通常の関数になっており、バッファに溜まっているイベントのみが取得できます。
もう溜まっているイベントがないか、チャンネルがクローズされている時にgetOrNullがnullを返すので、そのタイミングでループを抜けて変換の処理を行います。
これを使うことで、同時に来たイベントを一度に処理することができます。
Channel.tryReceiveを使うには、チャンネルのバッファを指定する必要があることに注意してください。
各Flowの結果を同時に受け取れるよう、チャンネルのバッファにはFlowの数を指定しています。
ちなみにDispatchers.Main.immediateを使った場合は、それぞれのFlowが即座に処理されるため、結果が異なることに注意してください。
まとめ
Flow.combineの実装方法について紹介していきました。
今回は主要部分を紹介するために一部を抜粋しているので、実際のコードは以下を見てください。
今回紹介した内容に加え、公式のコードには以下のような要素が含まれています。
- combineTransformと共通化
- sourceのFlowのキャンセルを伝播させる
- 同じFlowから連続した値を受け取ったらすぐに処理する
- 細かいパフォーマンス改善
Array(size) { UNINITIALIZED }の代わりにfill(UNINITIALIZED)を使うremainingAbsentValuesを使ってループ処理を減らす
今回Flow.combineの実装を読んで再現することで、スレッド安全にしたり、同時に発生したイベントをまとめて処理するために、Channelが有効であることを学ぶことができました。
また、パフォーマンスを改善するためのハックについても知ることができました。
これらを応用することで、複雑なFlowを扱うオペレータを自作する際に役立つと考えています。
すでに公式ライブラリ等で提供されているものを、改めて自分で作り直すことは「車輪の再開発」とも呼ばれ、あまり良くないとされています。
ただし、こうやって改めて自分の手を動かして書いてみることで、得られる学びは大きいと考えています。
実際にコードで利用しないことが条件ですが、ぜひとも色んな内部コードを読んで、手を動かして試してみてほしいと思います。